

Cloud data platforms really gained momentum in 2020. It has been a real breakout year for both cloud data lakes and cloud data warehouses (yeah, I am making a distinction). Cloud data warehouses started several years ago with Redshift and the first iteration of BigQuery. Databricks, AWS, Presto and others re-established the data lake in the cloud and made it very SQL friendly. Redshift and BigQuery have improved and made it possible and easier to now query external data lake storage directly (partitioned parquet, avro, csv....etc) and started to blend data lakes with data warehouses (somewhat). And to top it off this year, Snowflake put a massive stamp on everything with its financial market boom and accelerating adoption.
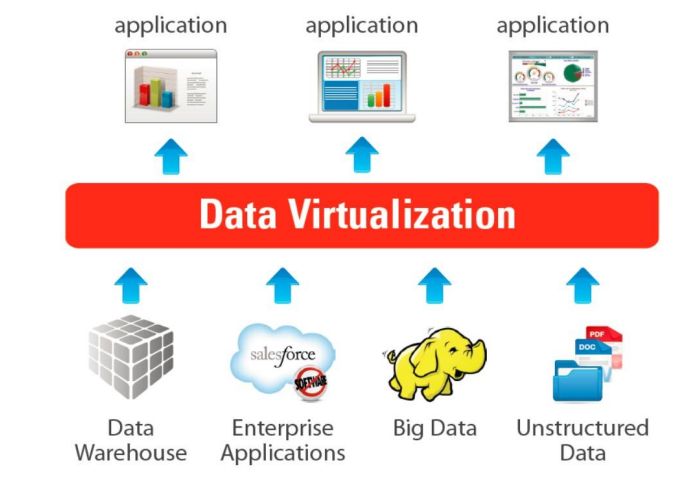
But we are still in the early days of the cloud data platform journey. We got a ways to go. Even with the cloud many of the solutions mentioned, along with others, still lock you into their propriety data walled gardens. In 2021 we will begin to see the next evolution of cloud data lakes/warehouses. It is not enough to separate compute from storage and just leverage the endless sea of elastic cloud storage and object storage. While this is an important step forward for data and analytics platforms, we need to go still further. We need to separate the query engine itself from the data and storage. This is the next step and it will be guided in part by leveraging data virtualization and establishing the physical storage structure of the data itself upon open standards.
Data Virtualization will gain more traction (especially in the cloud) and begin to eclipse and encompass data warehousing and in particular for low latency BI and analytics where it already plays a big role. Minimizing data copying in your data lake/warehouse is important especially for your the semantic and BI layers in your lake which can often demand highly curated and optimized models.
The key building blocks will include an open data lake foundation combined with data federation and high performance virtualization query engines coupled with cloud storage. And all on open standards. Think Apache Iceberg, Apache Hudi, Delta Lake, Apache Arrow, Project Nessie and other emerging open and cloud optimized big data standards.
Solutions such as Snowflake, Redshift, BigQuery, and Databricks are still potential plug-able building blocks, but should not be confused as the sole foundation or centerpiece for your cloud data platform, otherwise you will be walling yourself off all over again with another Teradata, Netezza or Oracle, just this time in the cloud.